신찬수 교수님의 유튜브 자료구조 강의를 시청하며 강의 내용을 정리한 글입니다. 강의를 시청하면서 이해한 개념들을 하나씩 정리하고, 이후에도 계속해서 내용을 추가해 나갈 예정입니다.
List
Python에서의 List는 읽기/쓰기 이외에 유연한 삽입/삭제 연산을 지원합니다.
1 | |
Queue
queue는 먼저 저장한 데이터가 먼저 출력되는 선입선출 FIFO 형식으로 데이터를 저장하는 자료구조입니다.
queue의 뒤에서 데이터를 추가하는 것을 enqueue, 앞에서 데이터를 꺼내는 것을 dequeue라고 합니다.(stack에서 enqueue = push, dequeue =pop)
1 | |
Queue를 클래스로 구현해봅니다.
1 | |
Queue 클래스를 구현한 뒤 이를 이용하여 요세푸스 문제를 풀어보았습니다.
1 | |
Linked List (연결 리스트)
Linked List는 Node(key, link)라는 구조체가 연결되는 형식으로 데이터를 저장하는 자료구조 입니다.
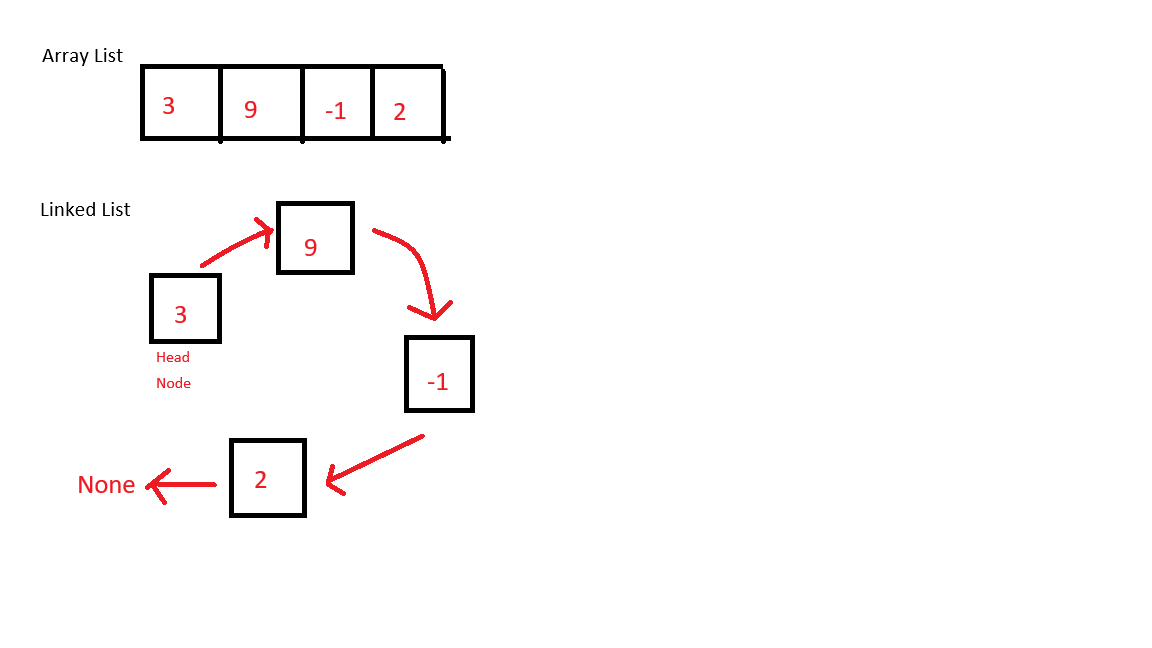
ArrayList와 LinkedList의 차이점
Array는 메모리 상에서 연속되 공간을 차지하기 때문에, 각 요소는 인덱스를 통해 직접 접근할 수 있습니다.
배열의 시작 주소를 알고 있다면 i 번째 인덱스의 요소를 읽거나 수정하는데 O(1)의 시간복잡도를 가집니다.
조회 성능이 매우 빠른 것이 장점이라면, 중간에 요소를 삽입하거나 삭제를 하기 위해선 뒤에 있는 요소들을 모두 이동(O(n))시켜야 하므로, 이 경우에는 성능이 저하될 수 있습니다.
LinkedList는 Node라는 단위로 구성되며, 각 Node는 데이터 값과 다음 노드를 가리키는 주소를 함께 저장합니다.
이 구조는 메모리 상에서 연속성을 유지하지 않으며, 특정 인덱스의 요소로 접근하기 위해서는 Head Node부터 시작하여 순차적으로 다음 노드를 따라가야 합니다.
두 번째 요소에 접근하려면 Head Node 부터 시작하여 두 번 이동해야 하므로, O(n)의 시간복잡도를 가집니다.
노드 간의 연결만 변경하면 되기 때문에 중간 삽입이나 삭제는 O(1)에 가깝게 처리할 수 있습니다.
LinkedList에는 한방향 연결리스트, 양방향 연결리스트가 있습니다.
한방향 연결리스트(Singly Linked List)는 Node 객체들이 연결된 구조로 이루어져 있습니다.
Node 클래스를 구현해 봅니다.
Singly Linked List 기본
1 | |
각 Node는 각각의 변수에 할당되어 있지만, 실제로 연결리스트를 순회하는 데에는 모든 노드의 변수를 알고 있을 필요가 없습니다.
첫 번째 노드인 Head Node만 알고 있으면, next 참조를 따라가면 나머지 모든 노드에 접근 할 수 있습니다.
SinglyLinkedList 클래스를 구현합니다. 기본 구성요소를 정의하고, 노드의 삽입과 삭제를 처리하는 메서드를 구현합니다.
1 | |
Singly Linked List 삽입, 삭제
1 | |
1 | |
1 | |
Singly Linked List 탐색 + 제너레이터
한방향 연결리스트에서 노드를 탐색하는 방법과, 탐색 로직을 제너레이터(generator) 로 구현하는 메서드를 구현합니다.
1 | |
제너레이터 함수는 반복 가능한 (iterable) 객체를 만들기 위해 사용하는 함수로, “for x in list” 와 같은 반복문에서 특히 유용합니다. 파이썬의 for문은 내부적으로 객체의 이터레이터(iterator)를 자동으로 요청하여 순차적으로 값을 가져옵니다.
따라서 for x in SinglyLinkedList 와 같은 형태의 반복을 지원하려면, 파이썬이 해당 객체를 어떻게 순회해야 하는지 알 수 있도록 이터레이터를 제공해야합니다. 이를 위해 연결리스트를 구현할 때 특수 메서드인 iterator를 정의하는 것이 바람직 합니다.
1 | |
yield는 함수의 실행을 완전히 종료하지 않고, 현재 상태를 유지한 채 값을 반환하는 키워드 입니다. yield가 포함된 함수는 제너레이터(generator)가 되며, 반복 요청이 있을 때 마다 값을 하나씩 반환합니다.
제너레이터 함수에서 더이상 yield 할 것이 없고 함수의 실행이 끝나면, 파이썬은 내부적으로 StopIteration 예외를 발생시켜 반복이 종료됩니다.
(순차적 자료구조에서 iterator 메서드를 구현해놓는 것이 좋습니다.)
Doubly Linked List 기본
한방향 연결리스트(Singly Linked List)는 각 노드가 다음 노드만을 가리키는 구조입니다. 이 구조에서는 tail 노드의 이전 노드(prev)를 알기 위해 처음부터 순회해야 하므로 O(n)의 시간이 소요되는 단점이 있습니다.
이러한 단점을 보완하기 위해 등장한 자료구조가 양방향 연결리스트(Double Linked List) 입니다. 양방향 연결 리스트는 각 노드가 이전 노드(prev)와 다음 노드(next)를 모두 가리키도록 구성되어 있어, 앞뒤 방향으로의 이동이 가능하며 특정 노드의 삭제나 삽입을 더 효율적으로 처리할 수 있습니다.
다만, 노드마다 관리해야 할 링크가 하나 더 늘어나기 때문에 메모리 사용량이 증가하고 구현 복잡도가 높아질 수 있다는 단점도 존재합니다.
원형 양방향 연결 리스트 (Circularly Doubly Linked List)
양방향 연결리스트를 확장한 형태로 원형 양방향 연결 리스트 (Circularly Doubly Linked List) 가 있습니다.
이 구조에서는
- tail 노드의 next가 head 노드를 가리키고
- head 노드의 prev가 tail 노드를 가리키는 방식
으로 연결되어, 리스트의 시작과 끝이 하나의 원으로 이어집니다.
이 구조를 구현할 때는 보통 빈 리스트를 하나의 노드로 표현하는데, 이를 dummy node라고 부릅니다.
dummy node는 실제 데이터를 저장하지 않으며, 리스트에서 어디가 시작인지 표시해주는 기준(마커)역할을 합니다.
1 | |
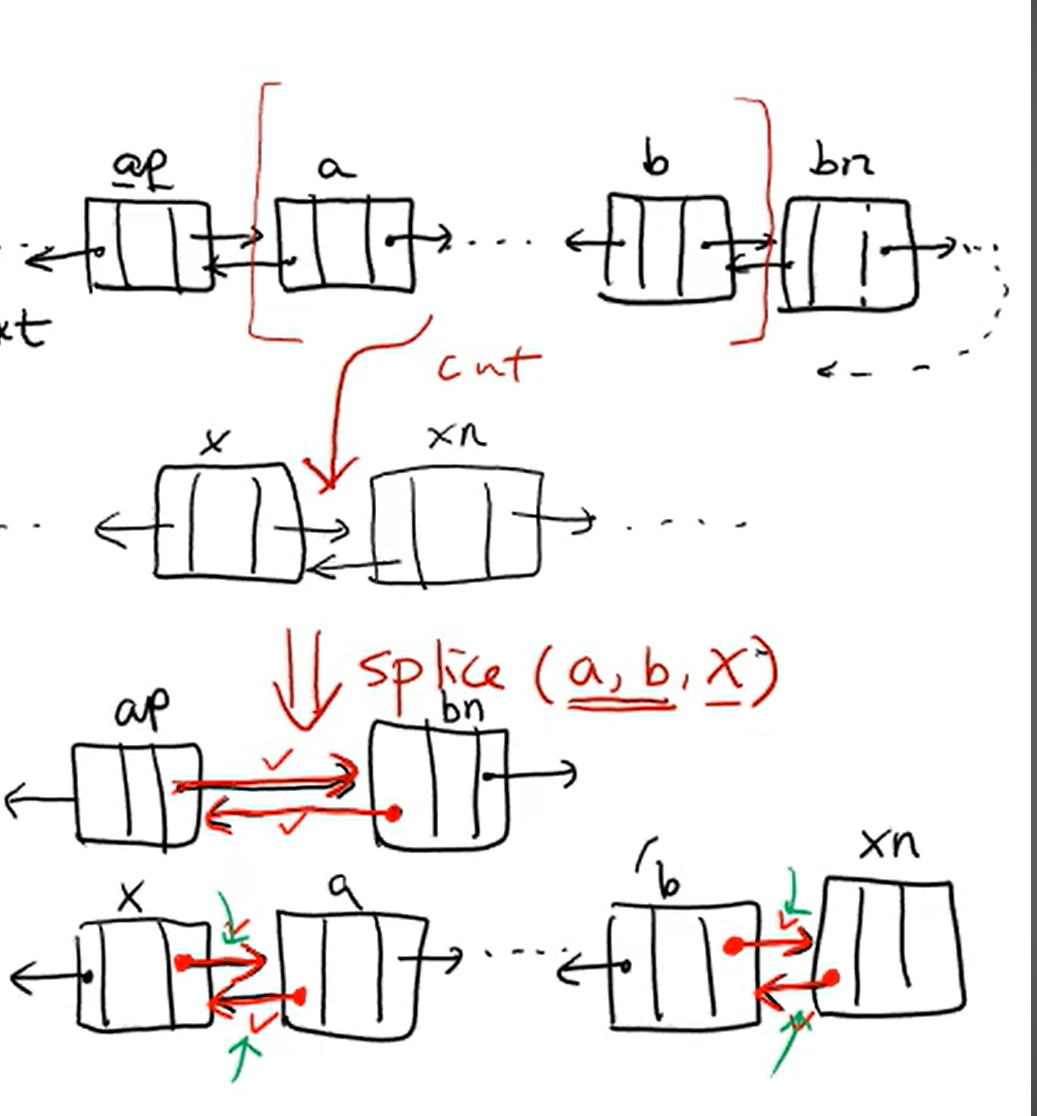
양방향 연결리스트에서 Splice 연산 적용
splice(a, b, x): 현재 리스트에서 연속 구간 [a,,,b] (a부터 b까지)를 잘라낸 다음, 노드 x 에 그 구간을 그대로 붙입니다.
Splice 연산의 조건
Splice 연산이 정상적으로 동작하기 위해서는 다음 조건들이 반드시 만족되어야 합니다.
- 조건 1: a -> … -> b 관계가 성립해야합니다.
- 조건 2: a와 b 사이에 head 노드가 존재하면 안됩니다.
1 | |
Splice 연산을 활용한 삽입, 이동, 탐색, 삭제 연산
이동연산
이동연산에는 총 4개의 함수가 있습니다. moveAfter/Before, insertAfter/Before
1 | |
탐색연산
1 | |
삭제연산
1 | |
해시 테이블 (Hash Table)
해시 테이블(Hash Table)은 삽입, 삭제, 탐색 연산을 평균적으로 O(1)이라는 매우 빠른 시간 복잡도로 수행할 수 있는 자료구조 입니다.
파이썬에서는 해시 테이블이 dictionary(dict) 현태로 구현되어 있습니다.
파이썬 Dictionary 구조
dictionary는 key-value 쌍 으로 데이터를 저장합니다.
1 | |
key: 학번 - value: 이름 형태로 선언되었습니다.
여기서 각 key는 해시 함수(hash function)을 통해 특정 인덱스로 변환되어 테이블에 저장됩니다.
해시 함수와 인덱싱
예를 들어 해시함수가 다음과 같다고 가정해봅니다.
1 | |
이 경우, 해시 테이블의 인덱스는 0~9가 됩니다.
1 | |
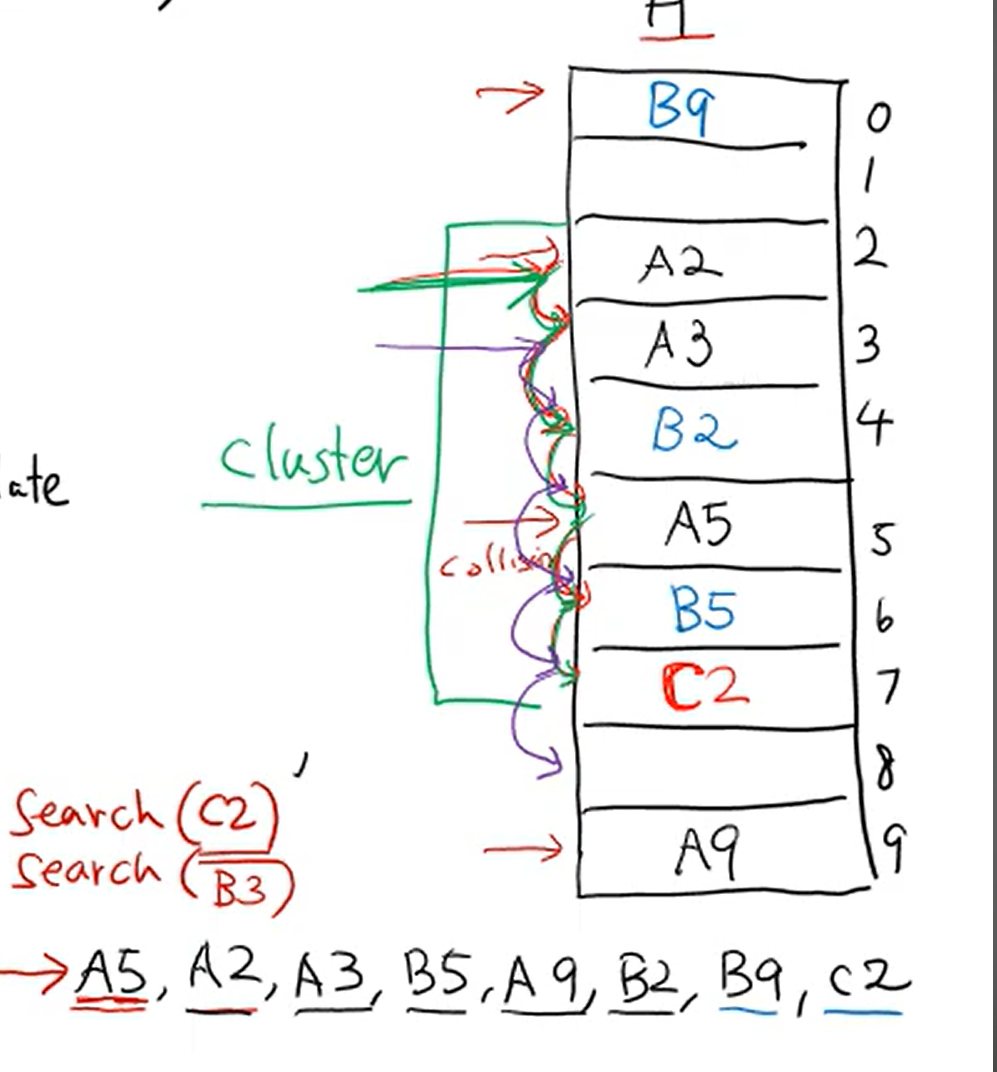
이 때 김철수와 톰크루즈는 동일한 인덱스인 9에 매핑됩니다.
Collision
이미 9번 인덱스에 김철수가 저장되어 있는데, 같은 위치에 톰 크루즈를 저장하려고 하면 문제가 발생합니다.
이처럼 서로 다른 key가 동일한 해시 값(인덱스)을 가지는 현상을 Collision(충돌) 이라고 합니다.
충돌은 해시테이블에서 피할 수 없는 문제이며, 이를 해결하기 위한 전략을 Collision Resolution Method 라고 합니다.
해시 테이블의 구성 요소
- Table(보통 배열 or 리스트)
- Hash Funciton
- Collision Resolution Method
좋은 해시 함수란 ?
해시 함수는 다음과 같은 성질을 갖는 것이 이상적입니다.
- 충돌이 적을 것
- Key들이 테이블 전체에 고르게 분포 될 것
이론적으로 충돌이 절대 발생하지 않는 해시 함수, Perfect Hash Function이 가장 이상적입니다.
그러나, PHF는
- 모든 key 집합을 미리 알고 있어야 하고,
- 동적 데이터에는 적용하기 어렵기 때문에
현실적으로 사용하기란 어렵습니다.
Universal Hash Funtion
현실적인 대안으로 Universal Hash Function이 사용됩니다.
서로 다른 두 key x, y에 대해
1 | |
이 성질을 만족하면 universal hash function 이라고 합니다.
만약 충돌 확률이
1 | |
라면 이를 c-universal hash function 이라고 합니다.
대표적인 해시 함수 기법
- Division method
- Multiplication method
- Folding
- Mid-square method
충돌 회피 방법
앞서 살펴본 것 처럼 Perfect Hash Function(PHF)이 아닌 이상, 해시 테이블에서는 충돌(Collision) 이 반드시 발생합니다.
이미 어떤 slot에 다른 key가 저장되어 있을 때,
이 데이터를 어디에 저장할 것인가?
이 문제를 해결하는 방법을 충돌 회피 방법(Collision Resolution Method) 이라고 합니다.
Open Addressing 기법
충돌이 발생했을 때, 테이블 내부에서 다른 빈 공간을 찾아 저장하는 방식을 Open Addressing 이라고 합니다.
Open Addressing에는 대표적으로 다음과 같은 기법들이 있습니다.
- Linear Probing
- Quadratic Probing
- Double Hashing
Linear Probing
Linear Probing은 충돌이 발생하면 현재 위치에서 아래 방향(다음 인덱스)으로 한 칸씩 이동 하며 비어 있는 slot을 찾는 방식입니다.